# Import required packages
import torch
import numpy as np
import normflows as nf
from matplotlib import pyplot as plt
from tqdm import tqdm
device = 'cuda'18 Normalizing Flows
GANs are the first major generative modeling architecture we considered, but nowadays it’s no longer widely used. Although the sampling is easy, it usually has no data likelihood, and the training process is often unstable. Normalizing flows, on the contrary, have exact likelihoods we can train on, and the sampling process is also easy (albeit much slower). The exact likelihood is guaranteed by applying some specific constraints on the network architecture (invertibility), which makes the Jacobian determinant between distribution transformations easy to compute. Later, with diffusion models, we’ll relax the architecture constraints a little bit so that the network will no longer be invertible, and we will only be able to train on an approximation of the likelihood. But these relaxations allow for some much more expressive models and better sample quality.
Normalizing flows are called as such because they transform a probability distribution through a sequence of mappings of the same dimensionality (thus it flows), and the inverse mappings transform a complex data distribution into a normalized one, often the normal distribution (thus it normalizes). As we can see, diffusion models also roughly share the same concepts. Recent SOTA generative models are often a mixture of the two.
The general model structure goes as follows. We start with a latent variable \(\mathbf{z}\), distributed according to a simple distribution \(p_{\mathbf{z}}(\mathbf{z})\), a function \(\mathbf{x} = f(\mathbf{z}, \mathbf{w})\) parameterized by a neural network that transforms the latent space into the data space, and its inverse function \(\mathbf{z} = g(\mathbf{x}, \mathbf{w})= g(f(\mathbf{z}, \mathbf{w}), \mathbf{w})\) that transforms the data space back into the latent space. The data likelihood is then given by the change of variables formula:
\[ p_{\mathbf{x}}(\mathbf{x}|\mathbf{w}) = p_{\mathbf{z}}(g(\mathbf{x}, \mathbf{w})) \cdot |\det J(\mathbf{x})| \]
where \(J(\mathbf{x})\) is the Jacobian matrix of partial derivatives whose elements are given by:
\[ J_{ij}(\mathbf{x}) = \frac{\partial g_i(\mathbf{x}, \mathbf{w})}{\partial x_j}. \]
To make sure that transformation is invertible, function \(f\) has to be a one-to-one mapping, this adds some constraints on the architecture of the neural network. Also computing the determinant of the Jacobian matrix can be computationally expensive, so we might impose some further restrictions on the network structure to make it more efficient.
If we consider a training set \(\mathcal{D} = \{\mathbf{x}_1, \ldots, \mathbf{x}_N\}\) of independent data points, the log likelihood function
\[ \ln p(\mathcal{D}|\mathbf{w}) = \sum_{n=1}^N \ln p_{\mathbf{x}}(\mathbf{x}_n|\mathbf{w}) = \sum_{n=1}^N \left[ \ln p_{\mathbf{z}}(g(\mathbf{x}_n, \mathbf{w})) + \ln |\det J(\mathbf{x}_n)| \right] \]
will serve as the objective function to train the neural network. The first term is the log likelihood of the latent variable, the second term is the log determinant of the Jacobian matrix.
To be able to model a wide range of distributions, we want the transformation function \(\mathbf{x} = f(\mathbf{z}, \mathbf{w})\) to be highly flexible, so we use a deep neural network with multiple layers. We can ensure that the overall function is invertible if we make each layer of the network invertible. And the two terms in the data likelihood, the latent variable likelihood and the Jacobian determinant, can both be computed easily under such a layered structure, using the chain rule of calculus.
Here we will cover some of the most common types of normalizing flows, coupling flows, autoregressive flows, residual flows and its continuous extension, Neural ODE flows. With neural ODE flowing the frontier of normalizing flow models are meeting the frontier of diffusion models, where we are also trying to replace the layered, residual based diffusion process using differential equations. We will also take a look at flow matching, a recently proposed technique for efficiently training differential equation based models.
18.1 Coupling flows
Recall that in flow models we aim for the following goals:
- The transformation function \(f\) should be (easily enough) invertible, so that we can compute the latent variable likelihood.
- The Jacobian determinant of the transformation should be easy to compute, so that we can correct the latent likelihood to get the data likelihood.
- We should be able to sample from it. Once the above two are met, this is usually straightforward, although the computation cost might vary.
Each flow model will attempt to meet these goals in different ways. In coupling flows, for each layer of the network, we first split the latent variable \(\mathbf{z}\) into two parts \(\mathbf{z} = (\mathbf{z}_A, \mathbf{z}_B)\), then apply the following transformation:
\[ \begin{align} \mathbf{X}_A &= \mathbf{Z}_A, \\ \mathbf{X}_B &= \exp(s(\mathbf{Z}_A, w)) \odot \mathbf{Z}_B + b(\mathbf{Z}_A, w). \end{align} \]
The frist part \(\mathbf{X}_A\) is simply left unchanged, and all the efforts are put into transforming the second part \(\mathbf{X}_B\). The transformation is done by a neural network with parameters \(w\), which takes \(\mathbf{Z}_A\) as input and outputs two vectors \(s(\mathbf{Z}_A, w)\) and \(b(\mathbf{Z}_A, w)\) of the same dimensionality as \(\mathbf{Z}_B\). Besides, an \(\exp\) function is used to ensure that the Jacobian determinant is easy to compute.
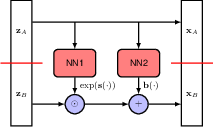
Now let’s check how this formula meets the three aformentioned goals. First is invertability. Simply rearrange the terms and we can get the inverse transformation:
\[ \begin{align} \mathbf{Z}_A &= \mathbf{X}_A, \\ \mathbf{Z}_B &= (\mathbf{X}_B - b(\mathbf{X}_A, w)) \odot \exp(-s(\mathbf{X}_A, w)). \end{align} \]
Notice how the inverse transformation does not involve inverting the neural networks at all, just changing the sign of the \(\exp\) function. This is the key to making the transformation invertible easy and efficient.
Second is computing the Jacobian determinant. It turns out the Jacobian is a lower trianglular matrix
\[ \begin{bmatrix} \mathbf{I} & 0 \\ \frac{\partial \mathbf{Z}_B}{\partial \mathbf{X}_A} & \text{diag}(-\exp(s(\mathbf{Z}_A, w))) \end{bmatrix} \]
and the determinant is simply the product of the diagonal elements.
- \(\mathbf{Z}_A\) is an identity transformation of \(\mathbf{X}_A\), so \(\frac{\partial \mathbf{Z}_A}{\partial \mathbf{X}_A}\) is an identity matrix.
- \(\frac{\partial \mathbf{Z}_A}{\partial \mathbf{X}_B}\) is zero.
- \(\mathbf{Z}_B\) is \(\mathbf{X}_B\) minus a linear transformation of \(\mathbf{X}_A\) (doesn’t involve \(\mathbf{Z}_B\)), then element-wise multiplied by the exponential term (meaning no interaction among \(\mathbf{Z}_B\)), so \(\frac{\partial \mathbf{Z}_B}{\partial \mathbf{X}_B}\) is a diagonal matrix, and the diagonal values are the corresponding negatives of the exponential term. Up to this point we know the Jacobian matrix itselve is a lower triangular matrix.
- \(\frac{\partial \mathbf{Z}_B}{\partial \mathbf{X}_A}\) is more complicated, but it doesn’t factor into the Jacobian determinant so can be safely ignored.
To make the network more expressive, normalizing flows often have multiple coupling layers stacked together, switching the roles of \(\mathbf{Z}_A\) and \(\mathbf{Z}_B\) at each layer, and possibly also changing the split points at each layer. The final data likelihood is the product of the likelihoods at each layer. And the Jacobian determinant is the product of the determinants at each layer.
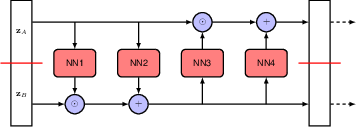
Third is sampling. Once the model is trained, we can start with \(\mathbf{Z}_A\), and follow the flow till we get to \(\mathbf{X}\). The sampling process is deterministic and easy to compute.
As an example we can train a normalizing flow model on a two-moons dataset, using the normflows package. The following code is adapted from the package’s example code.
This is the target distribution
# Define target distribution
target = nf.distributions.TwoMoons()
# Plot target distribution
grid_size = 200
xx, yy = torch.meshgrid(torch.linspace(-3, 3, grid_size), torch.linspace(-3, 3, grid_size), indexing='xy')
zz = torch.cat([xx.unsqueeze(2), yy.unsqueeze(2)], 2).view(-1, 2)
zz = zz.to(device)
log_prob = target.log_prob(zz).to('cpu').view(*xx.shape)
prob = torch.exp(log_prob)
prob[torch.isnan(prob)] = 0
plt.pcolormesh(xx, yy, prob.data.numpy(), cmap='hot')
plt.gca().set_aspect('equal', 'box')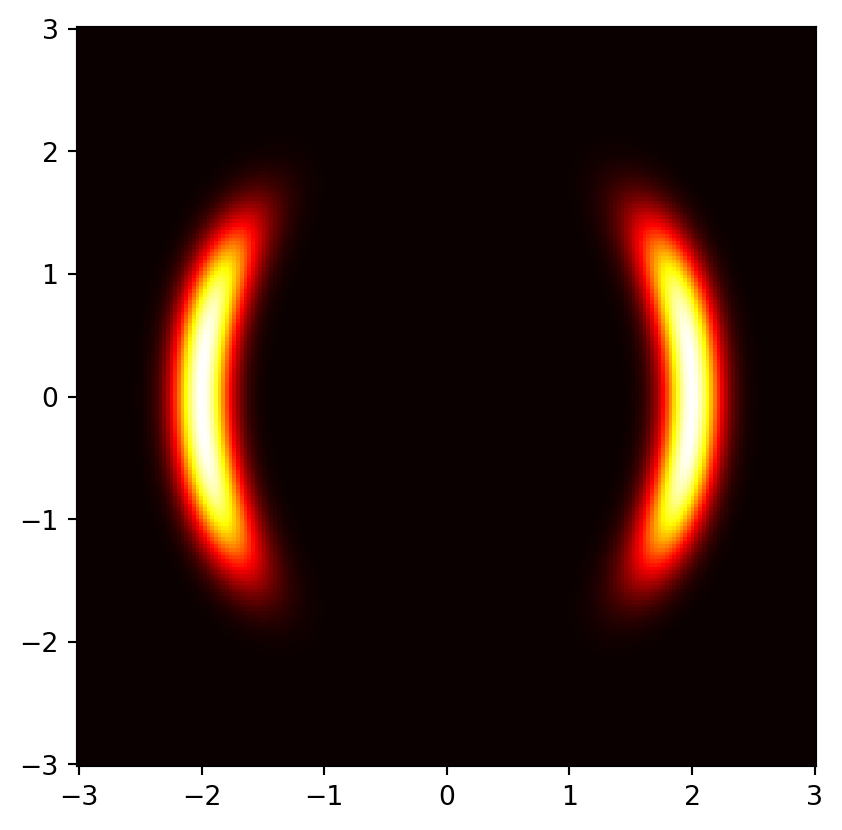
Construct the model. To define a normalizing flow model, we first specify the base distribution and the transformation layers, and then combine them in the NormalizingFlow class.
# Define 2D Gaussian base distribution
base = nf.distributions.base.DiagGaussian(2)
# Define list of flows
num_layers = 2
flows = []
for i in range(num_layers):
# Neural network with two hidden layers having 64 units each
# Last layer is initialized by zeros making training more stable
param_map = nf.nets.MLP([1, 64, 64, 2], init_zeros=True)
# Add flow layer
flows.append(nf.flows.AffineCouplingBlock(param_map))
# Swap dimensions
flows.append(nf.flows.Permute(2, mode='swap'))
model = nf.NormalizingFlow(base, flows)
model = model.to(device)Train the model.
max_iter = 3201
num_samples = 2 ** 9
show_iter = 800
loss_hist = np.array([])
prob_list = []
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4, weight_decay=1e-5)
for it in tqdm(range(max_iter)):
optimizer.zero_grad()
# Get training samples
x = target.sample(num_samples).to(device)
# Compute loss
loss = model.forward_kld(x)
# Do backprop and optimizer step
if ~(torch.isnan(loss) | torch.isinf(loss)):
loss.backward()
optimizer.step()
# Log loss
loss_hist = np.append(loss_hist, loss.to('cpu').data.numpy())
# Save prob for later plotting
if it % show_iter == 0:
model.eval()
log_prob = model.log_prob(zz)
model.train()
prob = torch.exp(log_prob.to('cpu').view(*xx.shape))
prob[torch.isnan(prob)] = 0
prob_list.append(prob.data.numpy())
plt.plot(loss_hist) 0%| | 0/3201 [00:00<?, ?it/s] 0%| | 11/3201 [00:00<00:29, 109.71it/s] 2%|▏ | 55/3201 [00:00<00:10, 302.95it/s] 3%|▎ | 97/3201 [00:00<00:08, 353.19it/s] 4%|▍ | 141/3201 [00:00<00:07, 386.44it/s] 6%|▌ | 187/3201 [00:00<00:07, 409.83it/s] 7%|▋ | 233/3201 [00:00<00:07, 423.82it/s] 9%|▊ | 279/3201 [00:00<00:06, 432.92it/s] 10%|█ | 323/3201 [00:00<00:06, 430.85it/s] 12%|█▏ | 369/3201 [00:00<00:06, 438.81it/s] 13%|█▎ | 415/3201 [00:01<00:06, 443.67it/s] 14%|█▍ | 461/3201 [00:01<00:06, 446.60it/s] 16%|█▌ | 506/3201 [00:01<00:06, 444.93it/s] 17%|█▋ | 551/3201 [00:01<00:06, 440.09it/s] 19%|█▊ | 596/3201 [00:01<00:05, 439.51it/s] 20%|█▉ | 640/3201 [00:01<00:05, 439.00it/s] 21%|██▏ | 684/3201 [00:01<00:05, 437.07it/s] 23%|██▎ | 729/3201 [00:01<00:05, 438.43it/s] 24%|██▍ | 773/3201 [00:01<00:05, 437.61it/s] 26%|██▌ | 817/3201 [00:01<00:05, 433.61it/s] 27%|██▋ | 862/3201 [00:02<00:05, 435.33it/s] 28%|██▊ | 906/3201 [00:02<00:05, 432.15it/s] 30%|██▉ | 950/3201 [00:02<00:05, 433.52it/s] 31%|███ | 994/3201 [00:02<00:05, 431.11it/s] 32%|███▏ | 1038/3201 [00:02<00:05, 429.26it/s] 34%|███▍ | 1081/3201 [00:02<00:04, 428.54it/s] 35%|███▌ | 1126/3201 [00:02<00:04, 432.76it/s] 37%|███▋ | 1170/3201 [00:02<00:04, 430.26it/s] 38%|███▊ | 1214/3201 [00:02<00:04, 429.07it/s] 39%|███▉ | 1257/3201 [00:02<00:04, 427.33it/s] 41%|████ | 1300/3201 [00:03<00:04, 427.90it/s] 42%|████▏ | 1343/3201 [00:03<00:04, 424.54it/s] 43%|████▎ | 1386/3201 [00:03<00:04, 425.49it/s] 45%|████▍ | 1429/3201 [00:03<00:04, 425.52it/s] 46%|████▌ | 1473/3201 [00:03<00:04, 427.38it/s] 47%|████▋ | 1516/3201 [00:03<00:03, 426.00it/s] 49%|████▊ | 1559/3201 [00:03<00:03, 424.96it/s] 50%|█████ | 1602/3201 [00:03<00:03, 423.34it/s] 51%|█████▏ | 1647/3201 [00:03<00:03, 428.69it/s] 53%|█████▎ | 1690/3201 [00:03<00:03, 419.48it/s] 54%|█████▍ | 1733/3201 [00:04<00:03, 421.89it/s] 55%|█████▌ | 1776/3201 [00:04<00:03, 421.52it/s] 57%|█████▋ | 1819/3201 [00:04<00:03, 414.22it/s] 58%|█████▊ | 1862/3201 [00:04<00:03, 417.40it/s] 60%|█████▉ | 1905/3201 [00:04<00:03, 419.26it/s] 61%|██████ | 1947/3201 [00:04<00:03, 415.89it/s] 62%|██████▏ | 1989/3201 [00:04<00:02, 416.85it/s] 63%|██████▎ | 2032/3201 [00:04<00:02, 418.09it/s] 65%|██████▍ | 2074/3201 [00:04<00:02, 417.17it/s] 66%|██████▌ | 2117/3201 [00:05<00:02, 420.19it/s] 67%|██████▋ | 2160/3201 [00:05<00:02, 421.98it/s] 69%|██████▉ | 2203/3201 [00:05<00:02, 421.50it/s] 70%|███████ | 2246/3201 [00:05<00:02, 422.99it/s] 72%|███████▏ | 2289/3201 [00:05<00:02, 424.32it/s] 73%|███████▎ | 2334/3201 [00:05<00:02, 430.28it/s] 74%|███████▍ | 2379/3201 [00:05<00:01, 435.78it/s] 76%|███████▌ | 2423/3201 [00:05<00:01, 432.82it/s] 77%|███████▋ | 2467/3201 [00:05<00:01, 429.39it/s] 78%|███████▊ | 2510/3201 [00:05<00:01, 427.75it/s] 80%|███████▉ | 2553/3201 [00:06<00:01, 427.39it/s] 81%|████████ | 2596/3201 [00:06<00:01, 427.28it/s] 82%|████████▏ | 2639/3201 [00:06<00:01, 425.32it/s] 84%|████████▍ | 2682/3201 [00:06<00:01, 424.01it/s] 85%|████████▌ | 2725/3201 [00:06<00:01, 424.89it/s] 86%|████████▋ | 2768/3201 [00:06<00:01, 425.26it/s] 88%|████████▊ | 2811/3201 [00:06<00:00, 424.13it/s] 89%|████████▉ | 2854/3201 [00:06<00:00, 421.46it/s] 91%|█████████ | 2897/3201 [00:06<00:00, 421.48it/s] 92%|█████████▏| 2940/3201 [00:06<00:00, 418.77it/s] 93%|█████████▎| 2983/3201 [00:07<00:00, 420.74it/s] 95%|█████████▍| 3026/3201 [00:07<00:00, 422.01it/s] 96%|█████████▌| 3069/3201 [00:07<00:00, 423.36it/s] 97%|█████████▋| 3112/3201 [00:07<00:00, 423.18it/s] 99%|█████████▊| 3155/3201 [00:07<00:00, 420.18it/s]100%|█████████▉| 3198/3201 [00:07<00:00, 418.36it/s]100%|██████████| 3201/3201 [00:07<00:00, 423.49it/s]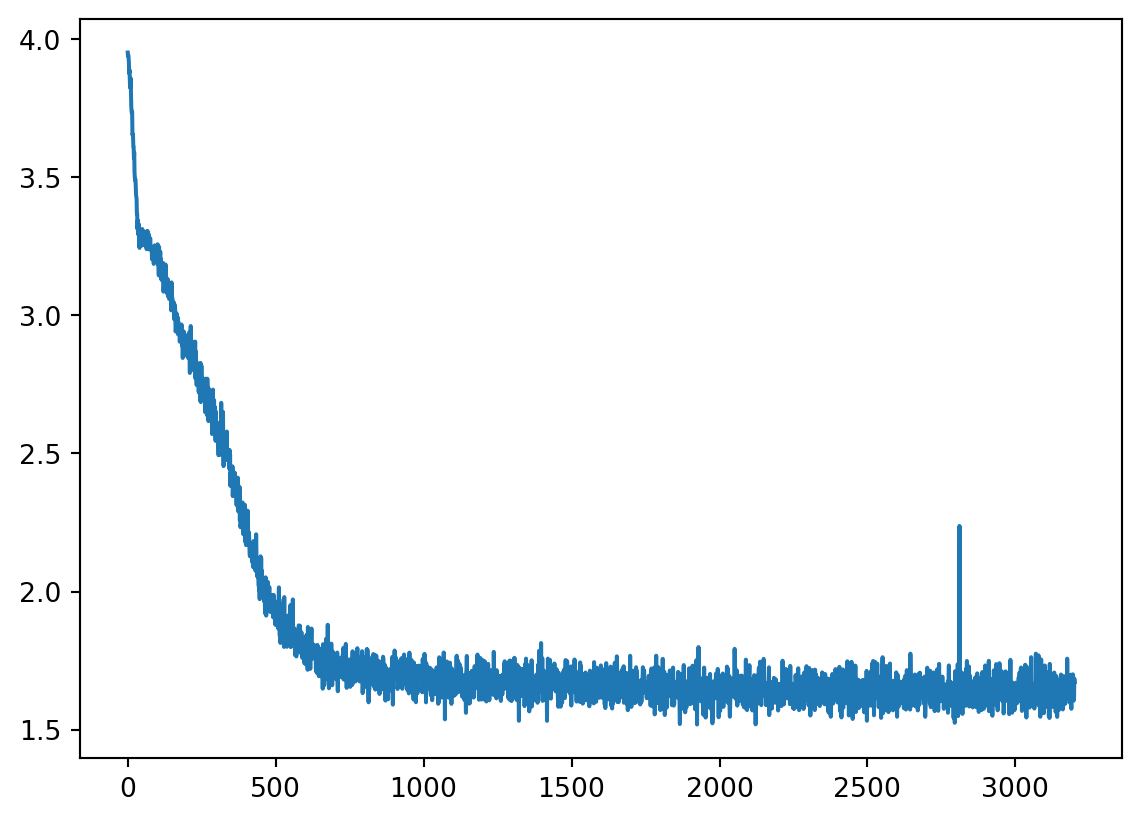
Plot the results. We can see that the model has (roughly) learned the distribution of the two moons dataset.
fig, axes = plt.subplots(1, len(prob_list), figsize=(10, 2), sharey=True)
for i, prob in enumerate(prob_list):
ax = axes[i]
c = ax.pcolormesh(xx, yy, prob, cmap='hot')
ax.set_aspect('equal', 'box')
# Adjust the colorbar to have more padding
cbar = fig.colorbar(c, ax=axes, orientation='vertical', fraction=0.02, pad=0.02)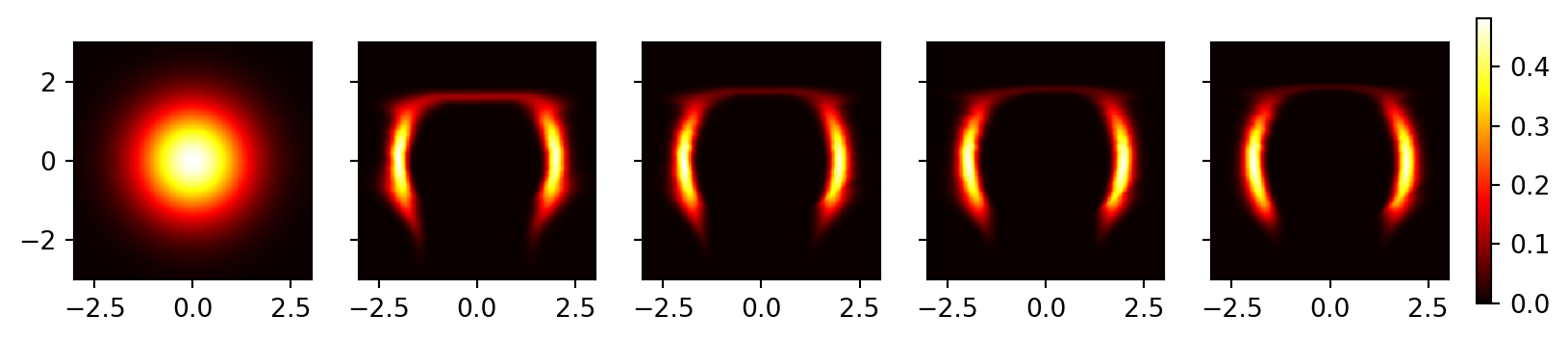
18.2 Autoregressive flows
18.3 Residual flows
18.4 Continuous flows
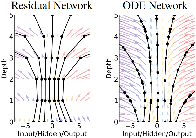
In normalizing flow models, for each transformation layer, the input and output always have the same dimensionality, we are thus looking for a more meaningful representation of the same data space. There is another neural network sharing this property, namely residual networks, but there is no guarantee that such a network will be invertible. Here we introduce a well known mathematical concept, the differential equation, into the neural network, and thus satisfying both the invertibility and the constant dimensionality requirements.
18.4.1 Neural differential equation
Neural differential equation, as the name implies, is a neural network that is defined by a differential equation. We can consider the residual network as a discrete version of the differential equation, since the “residual” is already a difference between consecutive layers, and the differential is the limit of this difference as it approaches zero. Thus starting from a residual network
\[ \mathbf{z}_{t+1} = \mathbf{z}_t + f(\mathbf{z}_t, \mathbf{w}) \]
we can readily convert it into a differential equation
\[ \frac{d\mathbf{z(t)}}{dt} = f(\mathbf{z(t)}, \mathbf{w}). \]
Now defining something is easy, what really matters is what we can do with it. On the modeling side, starting from an initial state \(\mathbf{z}_0\), we no longer need to define the number of layers in the network. we can integrate the differential equation to get the state at any time \(t\),
18.4.2 Neural ODE backpropagation
18.4.3 Neural ODE flows


